Online Learning in Online Auctions
Dynamics in markets
Introduction
How complicated can it possibly be to sell a bottle of wine?
From this surprisingly straightforward question has arisen the fertile, if somewhat obscure, field of Auction Theory
Indeed, almost all ads on the internet are sold at auction in a highly automated manner (all of it happens while your page is loading, in about $50$ ms). Whether these auctions are priced efficiently, fairly, and transparently, is therefore a key, if largely ignored, question concerning our daily lives.
I won’t go into fairness here, but rather into questions of efficiency. In particular, I would like to answer the following questions:
- How to accurately determine the price to sell each bottle of wine to a buyer if I have, say, $10^{10}$ bottles?
- If I have $50$ ms between each sale to determine the price, can I still price effectively?
The Second Price Auction
To answer i. we need to start by thinking about the design of the auction itself. Having collected prospective buyers, do I ask them to submit rising bids publicly? Do I ask them to submit sealed envelopes and take the highest bid? Do I name descending prices until someone accepts? How much should the winner pay? Should I charge losers too?
The answers to the last two questions probably seem obvious, but they are surprisingly complex, and they heavily impact the equilibrium behaviour of the bidders. The choice of the seller often lands on the second price auction, in which the highest bidder wins and pays the smallest bid which still wins them the auction. Unlike the first price auction, in which you pay your own bid, this format incentivises players to bid according to the true value they assign to the item.
We will study a second price auction, but in order to avoid large losses, we will set a minimum price of sale, known as a reserve price, for each item and bidder, and announce them publicly. Setting an individualised reserve price is particularly important when there is a strong asymmetry in the way buyers value the item, which can lead the second-highest bid to be much lower than the winning bid and therefore to poor pricing.
This format leads to the following model. The seller sets reserve prices, and then the bidders submit bids. The seller takes the highest amongst them and checks that it passes the reserve price, and, if so, awards the item at a price equal to the maximum of the second highest bid and the reserve price of the winning bidder. We are interested in studying how a seller should set reserve prices when facing static (passive) bidders in this type of auction.
From the point of view of pricing, the seller sees a stream of bids $b_t$ drawn according to a random
A Peculiar ERM
To understand the structure of this problem, we should start by looking at an optimal solution given full access to $F$ instead of just samples $b_t$. The optimal reserve price $r^*$ is given by the monopoly price
Given a finite sample, the logical thing to do then is to try and maximise $\Pi^{\hat F}$, where $\hat F:= n^{-1}\sum_i^n \delta_{b_i}$ is the empirical distribution of some finite sample of bids. In doing so, we would be trying to maximise \[\Pi^{\hat F} = \frac r n \sum_t^n \1_{r\le b_t} \] which is a sawtooth-shaped function which has $n$ local maxima (one at each $b_i$), and therefore there isn’t much better to do than to keep a sorted list of bids and check $\Pi^{\hat F}$ at each value. This method converges as $\Oc(n^{-1})$ but costs $\Oc(n)$ in both time and memory at each step.
This gives a satisfying answer to question i., but not a satisfying answer in practice. If you are to determine $r^*$ in $50$ ms, and you have billions of bottles to sell, even linear complexity is too expensive, you would have to stagger updates at, say, exponentially growing intervals while running week-long calculations, which will become month-long next time. If you want to be able to update online (after every auction), you need the update cost to be $\Oc(1)$ like a stochastic gradient (SG) method.
Backtracking one second, why didn’t we do SG in the first place? To converge this method needs two things: a sufficiently concave objective, which we have, and an unbiased estimate of the gradient at each step, which we don’t. The problem is that $p(r,b)= r\1_{r\le b}$ is discontinuous and therefore doesn’t allow us to commute the derivative and integral: \[ \int \1_{r\le b}\,\de F(b) \neq \frac{\de}{\de r} \int r\,\1_{r\le b}\,\de F(b) \,. \] If we want to design a stochastic gradient method for this problem, we need to overcome this difficulty.
Smoothed Gradient Descent
The obvious answer to discontinuity is to smooth the integrand $p$, say by convolution with the kernel $k\in\Cc^1$. Then $p_k(r,b_t)$ is an unbiased estimator for $\Pi_k^F$, where $p_k(\cdot,):=p(\cdot,)\star k$ and $\Pi^F_k:=\Pi^F\star k$. Ascending $\frac\de{\de r} p_k$ from samples $(b_t)_{i\in\Nb}$ should then converge to the optimum $r^*_k$ of $\Pi^F_k$. Or does it?
The subtle stumbling block we have just encountered is that convolution does not preserve the technical concavity condition for almost-sure convergence of iterates of gradient ascent
We have unearthed a highly obscure question of Analysis in this seemingly innocent problem, which thankfully is (partially) solved: which smooth functions preserve pseudo-concavity under convolution? An old paper
Bias-Variance trade-off
The problem with smoothing is that there is no reason for $\Pi^F$ and $\Pi_k^F$ to have the same minimiser, in other words, \(r^{*}_k \neq r^*\) for $\sigma>0$. So we want $\sigma$ to be as small as possible for the bias \(\vert r^{*}_k - r^*\vert\) to be small, but we also know that the gradient estimate breaks as $\sigma\to 0$. What happens will be clear in Figure 1.
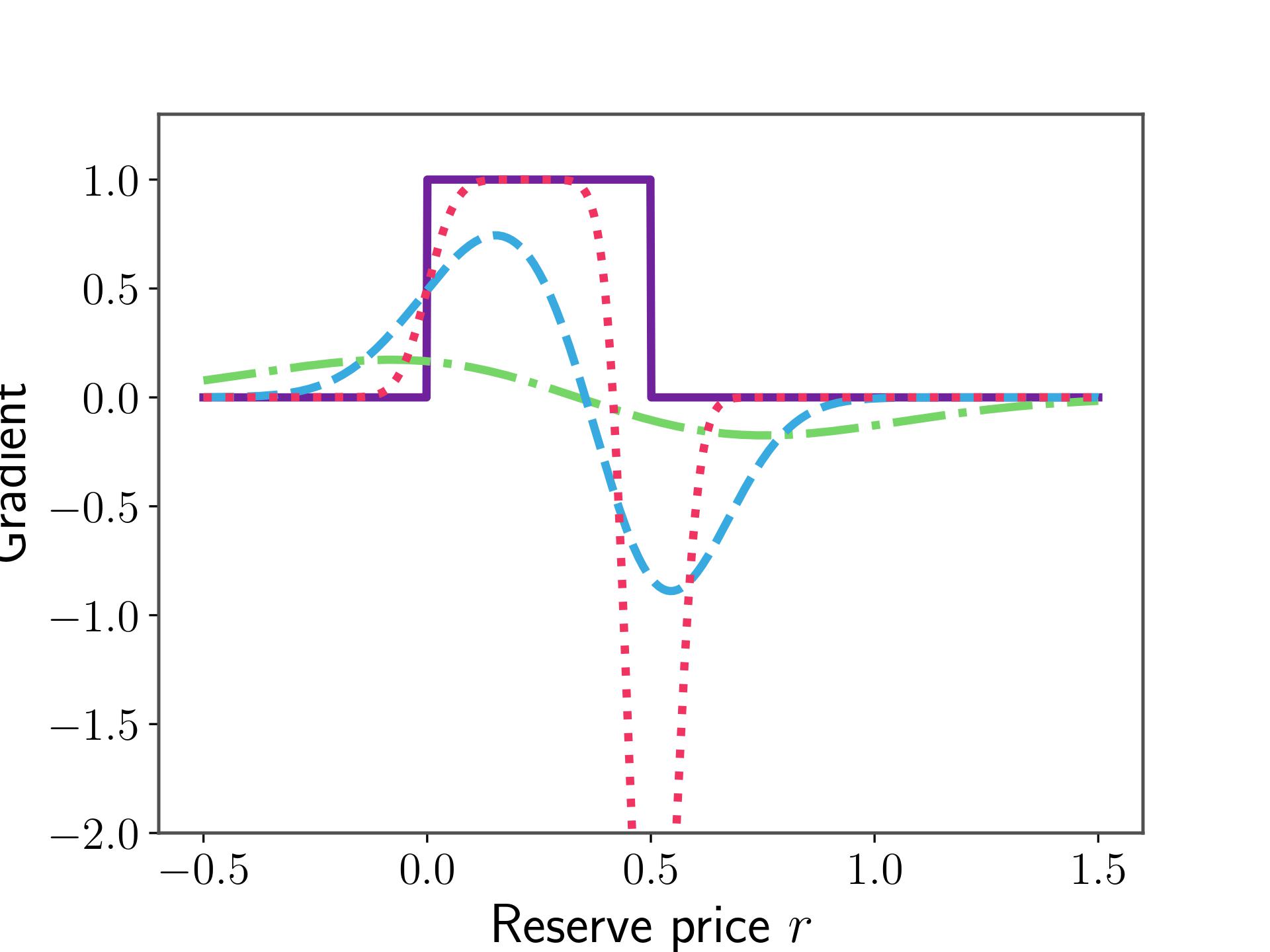
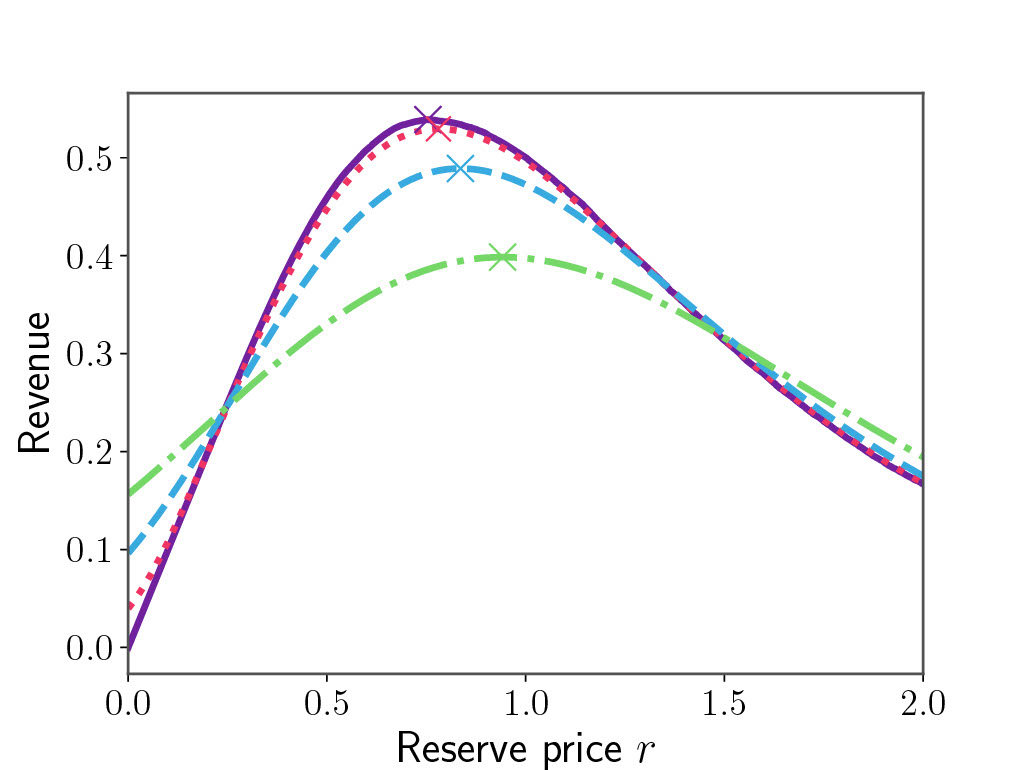
When $\sigma$ is large the curve is very smooth, and no value of $b$ will lead to a large gradient, which is to say a large change in the iterates $\vert r_{t+1}-r_{t}\vert$. We expect the trajectory of iterates to have very low variance as a consequence, but the bias might be large. Conversely, as the approximation gets better, the gradient of $p_k$ gets arbitrarily large near $r$, which means that a sample landing here can send the iterates very far. In this case, the bias will be very low, since the curves are almost equal, but the variance will be very high.
This classical learning theory dilemma is solved by analysing the error $\vert r_t-r^*$ to find how to balance the bias and variance and decrease them both over time at the correct rate. Setting aside the details of the proof, we want to set $\sigma(t)\simeq t^{-\frac12}$ as the schedule for decreasing the variance. You can see in Figure 2. how decreasing $\sigma$ too quickly or too slowly ($t^{-\frac14}$ vs $t^{-\frac34}$) leads to smooth but biased convergence or unbiased but erratic convergence, respectively.
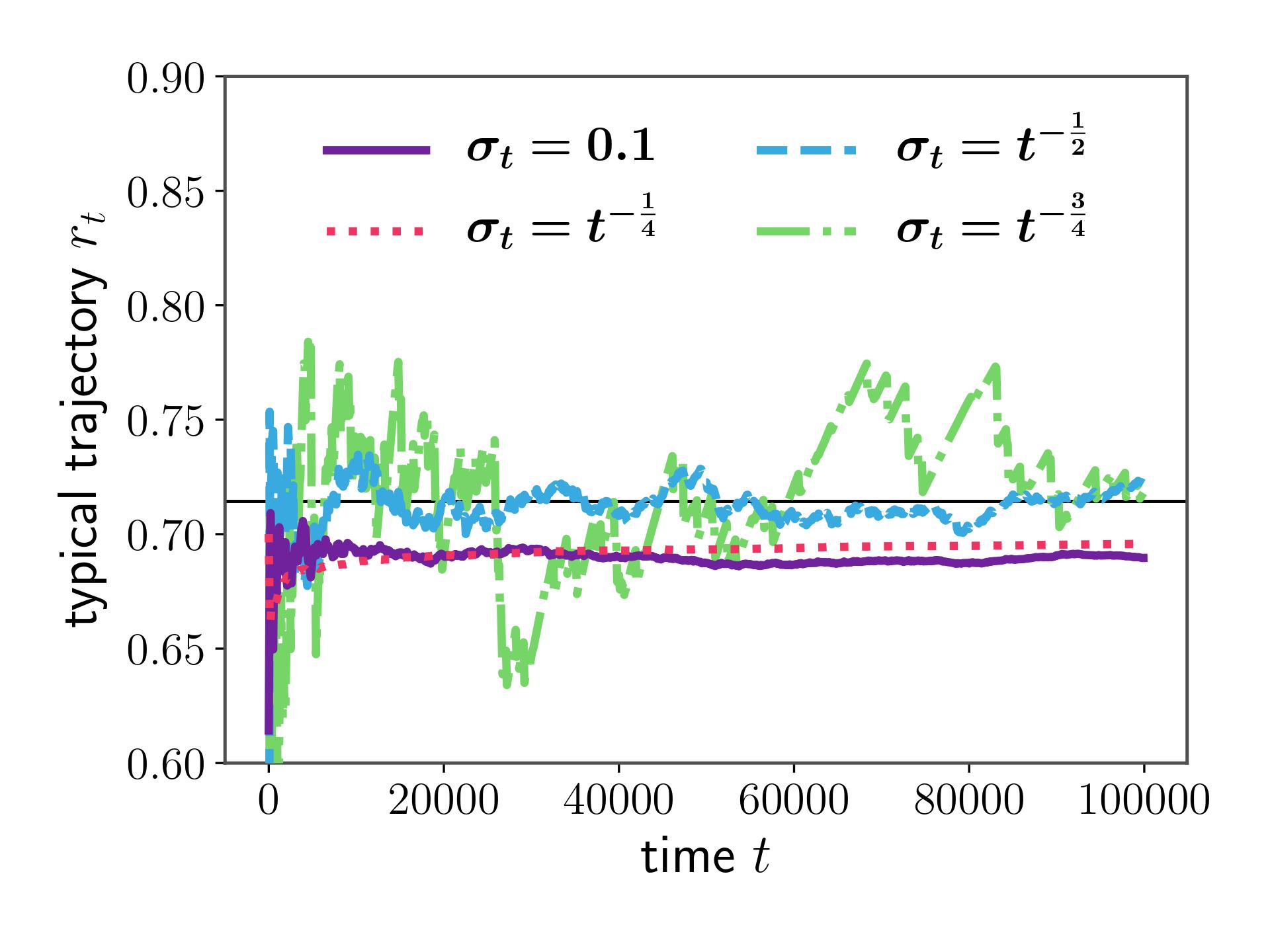
With this choice of $\sigma(t)$ we have therefore designed a method which converges to the optimum and only requires $\Oc(1)$ update cost in time and memory, which answers ii. In the paper, we show that the rate of convergence of this algorithm is $\Oc(t^{-\frac12})$.
Conclusion
In this project, the objective is to propose learning algorithms specifically tailored to auction theoretic problems, with an eye on computational efficiency. This is motivated by the scale at which internet ad auctions are run, which leaves existing methods computationally obsolete.
In
All in all, it is surprisingly complicated to sell a bottle of wine properly!
Extensions
The mathematical interest of this problem mostly lies first in unusual probabilistic problems, such as the question over which convolutions preserve some relaxed form of convexity, and second in quantifying computational trade-offs.
In the first vein, we have barely scratched the surface of the problem: other auction formats, strategic bidders, bandit/censored feedback, and more exist to complexify the problem. One key extension which is surprisingly difficult is to turn the bid into a function of some public features $x_t\in\Rb^d$ and try and learn a model of this function. It is non-trivial to extend the convolution method above to this problem since composition does not preserve pseudo-concavity. Following Ibragimov, finding the class of functions which preserves pseudo-concavity by composition should tell us something about which functions preserve the unimodality of random variables, which is doubtless an interesting problem for probabilists.
In the second vein, on the other hand, the tantalising question is whether there is an algorithm which costs only $\Oc(1)$ at each step which achieves the rate $\Oc(t^{-1})$? It might be possible with second-order methods, but the question suggests a notion of convergence hardness under computational constraints which I don’t think I have seen explored before.
However, given some a priori information about $F$, I think it would be possible to find a well-tuned kernel which performs much better than Gaussian. This is suggested by the asymmetry of the problem (because $p$ is highly asymmetrical), which would encourage us to intentionally bias a low variance kernel to counteract its natural bias, for example by using an asymmetrical kernel like a Gumbel distribution. In general, the question of the optimal kernel for a given $F$ might yield interesting insights.